Что характеризует среднеквадратическое отклонение. Дисперсия. Среднее квадратическое отклонение
В данной статье я расскажу о том, как найти среднеквадратическое отклонение . Этот материал крайне важен для полноценного понимания математики, поэтому репетитор по математике должен посвятить его изучению отдельный урок или даже несколько. В этой статье вы найдёте ссылку на подробный и понятный видеоурок, в котором рассказано о том, что такое среднеквадратическое отклонение и как его найти.
Среднеквадратическое отклонение дает возможность оценить разброс значений, полученных в результате измерения какого-то параметра. Обозначается символом (греческая буква «сигма»).
Формула для расчета довольно проста. Чтобы найти среднеквадратическое отклонение, нужно взять квадратный корень из дисперсии. Так что теперь вы должны спросить: “А что же такое дисперсия?”
Что такое дисперсия
Определение дисперсии звучит так. Дисперсия — это среднее арифметическое от квадратов отклонений значений от среднего.
Чтобы найти дисперсию последовательно проведите следующие вычисления:
- Определите среднее (простое среднее арифметическое ряда значений).
- Затем от каждого из значений отнимите среднее и возведите полученную разность в квадрат (получили квадрат разности ).
- Следующим шагом будет вычисление среднего арифметического полученных квадратов разностей (Почему именно квадратов вы сможете узнать ниже).
Рассмотрим на примере. Допустим, вы с друзьями решили измерить рост ваших собак (в миллиметрах). В результате измерений вы получили следующие данные измерений роста (в холке): 600 мм, 470 мм, 170 мм, 430 мм и 300 мм.
Вычислим среднее значение, дисперсию и среднеквадратическое отклонение.
Сперва найдём среднее значение . Как вы уже знаете, для этого нужно сложить все измеренные значения и поделить на количество измерений. Ход вычислений:
Среднее мм.
Итак, среднее (среднеарифметическое) составляет 394 мм.
Теперь нужно определить отклонение роста каждой из собак от среднего :

Наконец, чтобы вычислить дисперсию , каждую из полученных разностей возводим в квадрат, а затем находим среднее арифметическое от полученных результатов:
Дисперсия мм 2 .
Таким образом, дисперсия составляет 21704 мм 2 .
Как найти среднеквадратическое отклонение
Так как же теперь вычислить среднеквадратическое отклонение, зная дисперсию? Как мы помним, взять из нее квадратный корень. То есть среднеквадратическое отклонение равно:
Мм (округлено до ближайшего целого значения в мм).
Применив данный метод, мы выяснили, что некоторые собаки (например, ротвейлеры) – очень большие собаки. Но есть и очень маленькие собаки (например, таксы, только говорить им этого не стоит).
Самое интересное, что среднеквадратическое отклонение несет в себе полезную информацию. Теперь мы можем показать, какие из полученных результатов измерения роста находятся в пределах интервала, который мы получим, если отложим от среднего (в обе стороны от него) среднеквадратическое отклонение.
То есть с помощью среднеквадратического отклонения мы получаем “стандартный” метод, который позволяет узнать, какое из значений является нормальным (среднестатистическим), а какое экстраординарно большим или, наоборот, малым.
Что такое стандартное отклонение
Но… все будет немного иначе, если мы будем анализировать выборку данных. В нашем примере мы рассматривали генеральную совокупность. То есть наши 5 собак были единственными в мире собаками, которые нас интересовали.
Но если данные являются выборкой (значениями, которые выбрали из большой генеральной совокупности), тогда вычисления нужно вести иначе.
Если есть значений, то:
Все остальные расчеты производятся аналогично, в том числе и определение среднего.
Например, если наших пять собак – только выборка из генеральной совокупности собак (всех собак на планете), мы должны делить на 4, а не на 5, а именно:
Дисперсия выборки =  мм 2 .
мм 2 .
При этом стандартное отклонение по выборке равно  мм (округлено до ближайшего целого значения).
мм (округлено до ближайшего целого значения).
Можно сказать, что мы произвели некоторую “коррекцию” в случае, когда наши значения являются всего лишь небольшой выборкой.
Примечание. Почему именно квадраты разностей?
Но почему при вычислении дисперсии мы берём именно квадраты разностей? Допустим при измерении какого-то параметра, вы получили следующий набор значений: 4; 4; -4; -4. Если мы просто сложим абсолютные отклонения от среднего (разности) между собой … отрицательные значения взаимно уничтожатся с положительными:
 .
.
Получается, этот вариант бесполезен. Тогда, может, стоит попробовать абсолютные значения отклонений (то есть модули этих значений)?
На первый взгляд получается неплохо (полученная величина, кстати, называется средним абсолютным отклонением), но не во всех случаях. Попробуем другой пример. Пусть в результате измерения получился следующий набор значений: 7; 1; -6; -2. Тогда среднее абсолютное отклонение равно:
Вот это да! Снова получили результат 4, хотя разности имеют гораздо больший разброс.
А теперь посмотрим, что получится, если возвести разности в квадрат (и взять потом квадратный корень из их суммы).
Для первого примера получится:
 .
.
Для второго примера получится:
Теперь – совсем другое дело! Среднеквадратическое отклонение получается тем большим, чем больший разброс имеют разности … к чему мы и стремились.
Фактически в данном методе использована та же идея, что и при вычислении расстояния между точками, только примененная иным способом.
И с математической точки зрения использование квадратов и квадратных корней дает больше пользы, чем мы могли бы получить на основании абсолютных значений отклонений, благодаря чему среднеквадратическое отклонение применимо и для других математических задач.
О том, как найти среднеквадратическое отклонение, вам рассказал , Сергей Валерьевич
Проведение любого статистического анализа немыслимо без расчетов. В это статье рассмотрим, как рассчитать дисперсию, среднеквадратичное отклонение, коэффиент вариации и другие статистические показатели в Excel.
Максимальное и минимальное значение
Среднее линейное отклонение
Среднее линейное отклонение представляет собой среднее из абсолютных (по модулю) отклонений от в анализируемой совокупности данных. Математическая формула имеет вид:
a – среднее линейное отклонение,
X – анализируемый показатель,
X̅ – среднее значение показателя,
n
В Эксель эта функция называется СРОТКЛ .

После выбора функции СРОТКЛ указываем диапазон данных, по которому должен произойти расчет. Нажимаем «ОК».
Дисперсия
{module 111}
Возможно, не все знают, что такое , поэтому поясню, — это мера, характеризующая разброс данных вокруг математического ожидания. Однако в распоряжении обычно есть только выборка, поэтому используют следующую формулу дисперсии:
![]()
s 2 – выборочная дисперсия, рассчитанная по данным наблюдений,
X – отдельные значения,
X̅ – среднее арифметическое по выборке,
n – количество значений в анализируемой совокупности данных.
Соответствующая функция Excel — ДИСП.Г . При анализе относительно небольших выборок (примерно до 30-ти наблюдений) следует использовать , которая рассчитывается по следующей формуле.
![]()
Отличие, как видно, только в знаменателе. В Excel для расчета выборочной несмещенной дисперсии есть функция ДИСП.В .

Выбираем нужный вариант (генеральную или выборочную), указываем диапазон, жмем кнопку «ОК». Полученное значение может оказаться очень большим из-за предварительного возведения отклонений в квадрат. Дисперсия в статистике очень важный показатель, но ее обычно используют не в чистом виде, а для дальнейших расчетов.
Среднеквадратичное отклонение
Среднеквадратичное отклонение (СКО) – это корень из дисперсии. Этот показатель также называют стандартным отклонением и рассчитывают по формуле:
по генеральной совокупности

по выборке

Можно просто извлечь корень из дисперсии, но в Excel для среднеквадратичного отклонения есть готовые функции: СТАНДОТКЛОН.Г и СТАНДОТКЛОН.В (по генеральной и выборочной совокупности соответственно).

Стандартное и среднеквадратичное отклонение, повторюсь, — синонимы.
Далее, как обычно, указываем нужный диапазон и нажимаем на «ОК». Среднеквадратическое отклонение имеет те же единицы измерения, что и анализируемый показатель, поэтому является сопоставимым с исходными данными. Об этом ниже.
Коэффициент вариации
Все показатели, рассмотренные выше, имеют привязку к масштабу исходных данных и не позволяют получить образное представление о вариации анализируемой совокупности. Для получения относительной меры разброса данных используют коэффициент вариации , который рассчитывается путем деления среднеквадратичного отклонения на среднее арифметическое . Формула коэффициента вариации проста:
Для расчета коэффициента вариации в Excel нет готовой функции, что не есть большая проблема. Расчет можно произвести простым делением стандартного отклонения на среднее значение. Для этого в строке формул пишем:
СТАНДОТКЛОН.Г()/СРЗНАЧ()
В скобках указывается диапазон данных. При необходимости используют среднее квадратичное отклонение по выборке (СТАНДОТКЛОН.В).
Коэффициент вариации обычно выражается в процентах, поэтому ячейку с формулой можно обрамить процентным форматом. Нужная кнопка находится на ленте на вкладке «Главная»:

Изменить формат также можно, выбрав из контекстного меню после выделения нужной ячейки и нажатия правой кнопкой мышки.
Коэффициент вариации, в отличие от других показателей разброса значений, используется как самостоятельный и весьма информативный индикатор вариации данных. В статистике принято считать, что если коэффициент вариации менее 33%, то совокупность данных является однородной, если более 33%, то – неоднородной. Эта информация может быть полезна для предварительного описания данных и определения возможностей проведения дальнейшего анализа. Кроме того, коэффициент вариации, измеряемый в процентах, позволяет сравнивать степень разброса различных данных независимо от их масштаба и единиц измерений. Полезное свойство.
Коэффициент осцилляции
Еще один показатель разброса данных на сегодня — коэффициент осцилляции. Это соотношение размаха вариации (разницы между максимальным и минимальным значением) к средней. Готовой формулы Excel нет, поэтому придется скомпоновать три функции: МАКС, МИН, СРЗНАЧ.

Коэффициент осцилляции показывает степень размаха вариации относительно средней, что также можно использовать для сравнения различных наборов данных.
В целом, с помощью Excel многие статистические показатели рассчитываются очень просто. Если что-то непонятно, всегда можно воспользоваться окошком для поиска во вставке функций. Ну, и Гугл в помощь.
При статистической проверке гипотез, при измерении линейной взаимосвязи между случайными величинами.
Среднеквадратическое отклонение:
Стандартное отклонение (оценка среднеквадратического отклонения случайной величины Пол, стены вокруг нас и потолок,x относительно её математического ожидания на основе несмещённой оценки её дисперсии):
где - дисперсия ; - Пол, стены вокруг нас и потолок,i -й элемент выборки; - объём выборки; - среднее арифметическое выборки:
Следует отметить, что обе оценки являются смещёнными. В общем случае несмещённую оценку построить невозможно. Однако оценка на основе оценки несмещённой дисперсии является состоятельной .
Правило трёх сигм
Правило трёх сигм () - практически все значения нормально распределённой случайной величины лежат в интервале . Более строго - не менее чем с 99,7 % достоверностью значение нормально распределенной случайной величины лежит в указанном интервале (при условии, что величина истинная, а не полученная в результате обработки выборки).
Если же истинная величина неизвестна, то следует пользоваться не , а Пол, стены вокруг нас и потолок,s . Таким образом, правило трёх сигм преобразуется в правило трёх Пол, стены вокруг нас и потолок,s .
Интерпретация величины среднеквадратического отклонения
Большое значение среднеквадратического отклонения показывает большой разброс значений в представленном множестве со средней величиной множества; маленькое значение, соответственно, показывает, что значения в множестве сгруппированы вокруг среднего значения.
Например, у нас есть три числовых множества: {0, 0, 14, 14}, {0, 6, 8, 14} и {6, 6, 8, 8}. У всех трёх множеств средние значения равны 7, а среднеквадратические отклонения, соответственно, равны 7, 5 и 1. У последнего множества среднеквадратическое отклонение маленькое, так как значения в множестве сгруппированы вокруг среднего значения; у первого множества самое большое значение среднеквадратического отклонения - значения внутри множества сильно расходятся со средним значением.
В общем смысле среднеквадратическое отклонение можно считать мерой неопределенности. К примеру, в физике среднеквадратическое отклонение используется для определения погрешности серии последовательных измерений какой-либо величины. Это значение очень важно для определения правдоподобности изучаемого явления в сравнении с предсказанным теорией значением: если среднее значение измерений сильно отличается от предсказанных теорией значений (большое значение среднеквадратического отклонения), то полученные значения или метод их получения следует перепроверить.
Практическое применение
На практике среднеквадратическое отклонение позволяет определить, насколько значения в множестве могут отличаться от среднего значения.
Климат
Предположим, существуют два города с одинаковой средней максимальной дневной температурой, но один расположен на побережье, а другой внутри континента. Известно, что в городах, расположенных на побережье, множество различных максимальных дневных температур меньше, чем у городов, расположенных внутри континента. Поэтому среднеквадратическое отклонение максимальных дневных температур у прибрежного города будет меньше, чем у второго города, несмотря на то, что среднее значение этой величины у них одинаковое, что на практике означает, что вероятность того, что максимальная температура воздуха каждого конкретного дня в году будет сильнее отличаться от среднего значения, выше у города, расположенного внутри континента.
Спорт
Предположим, что есть несколько футбольных команд, которые оцениваются по некоторому набору параметров, например, количеству забитых и пропущенных голов, голевых моментов и т. п. Наиболее вероятно, что лучшая в этой группе команда будет иметь лучшие значения по большему количеству параметров. Чем меньше у команды среднеквадратическое отклонение по каждому из представленных параметров, тем предсказуемее является результат команды, такие команды являются сбалансированными. С другой стороны, у команды с большим значением среднеквадратического отклонения сложно предсказать результат, что в свою очередь объясняется дисбалансом, например, сильной защитой, но слабым нападением.
Использование среднеквадратического отклонения параметров команды позволяет в той или иной мере предсказать результат матча двух команд, оценивая сильные и слабые стороны команд, а значит, и выбираемых способов борьбы.
Технический анализ
См. также
Литература
| Эта статья предлагается к удалению.
Пояснение причин и соответствующее обсуждение вы можете найти на странице Википедия:К удалению/17 декабря 2012.
|
* Боровиков, В. STATISTICA. Искусство анализа данных на компьютере: Для профессионалов / В. Боровиков. - СПб. : Питер, 2003. - 688 с. - ISBN 5-272-00078-1 .
| Статистические показатели | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Описательная статистика |
|
||||||||||
| Статистический вывод и проверка гипотез |
| ||||||||||
Полученные из опыта величины неизбежно содержат погрешности, обусловленные самыми разнообразными причинами. Среди них следует различать погрешности систематические и случайные. Систематические ошибки обусловливаются причинами, действующими вполне определенным образом, и могут быть всегда устранены или достаточно точно учтены. Случайные ошибки вызываются весьма большим числом отдельных причин, не поддающихся точному учету и действующих в каждом отдельном измерении различным образом. Эти ошибки невозможно совершенно исключить; учесть же их можно только в среднем, для чего необходимо знать законы, которым подчиняются случайные ошибки.
Будем обозначать измеряемую величину через А, а случайную ошибку при измерении х. Так как ошибка х может принимать любые значения, то она является непрерывной случайной величиной, которая вполне характеризуется своим законом распределения.
Наиболее простым и достаточно точно отображающим действительность (в подавляющем большинстве случаев) является так называемый нормальный закон распределения ошибок :
Этот закон распределения может быть получен из различных теоретических предпосылок, в частности, из требования, чтобы наиболее вероятным значением неизвестной величины, для которой непосредственным измерением получен ряд значений с одинаковой степенью точности, являлось среднее арифметическое этих значений. Величина 2 называется дисперсией данного нормального закона.
Среднее арифметическое
Определение дисперсии по опытным данным. Если для какой-либо величины А непосредственным измерением получено n значений a i с одинаковой степенью точности и если ошибки величины А подчинены нормальному закону распределения, то наиболее вероятным значением А будет среднее арифметическое :
a - среднее арифметическое,
a i - измеренное значение на i-м шаге.
Отклонение наблюдаемого значения (для каждого наблюдения) a i величины А от среднего арифметического : a i - a.
Для определения дисперсии нормального закона распределения ошибок в этом случае пользуются формулой:
2 - дисперсия,
a - среднее арифметическое,
n - число измерений параметра,
Среднеквадратическое отклонение
Среднеквадратическое отклонение показывает абсолютное отклонение измеренных значений от среднеарифметического . В соответствии с формулой для меры точности линейной комбинации средняя квадратическая ошибка среднего арифметического определяется по формуле:
![]() , где
, где
a - среднее арифметическое,
n - число измерений параметра,
a i - измеренное значение на i-м шаге.
Коэффициент вариации
Коэффициент вариации характеризует относительную меру отклонения измеренных значений от среднеарифметического :
![]() , где
, где
V - коэффициент вариации,
- среднеквадратическое отклонение,
a - среднее арифметическое.
Чем больше значение коэффициента вариации , тем относительно больший разброс и меньшая выравненность исследуемых значений. Если коэффициент вариации меньше 10%, то изменчивость вариационного ряда принято считать незначительной, от 10% до 20% относится к средней, больше 20% и меньше 33% к значительной и если коэффициент вариации превышает 33%, то это говорит о неоднородности информации и необходимости исключения самых больших и самых маленьких значений.
Среднее линейное отклонение
Один из показателей размаха и интенсивности вариации - среднее линейное отклонение (средний модуль отклонения) от среднего арифметического. Среднее линейное отклонение рассчитывается по формуле:
![]() , где
, где
_
a - среднее линейное отклонение,
a - среднее арифметическое,
n - число измерений параметра,
a i - измеренное значение на i-м шаге.
Для проверки соответствия исследуемых значений закону нормального распределения применяют отношение показателя асимметрии к его ошибке и отношение показателя эксцесса к его ошибке.
Показатель асимметрии
Показатель асимметрии (A) и его ошибка (m a) рассчитывается по следующим формулам:
![]() , где
, где
А - показатель асимметрии,
- среднеквадратическое отклонение,
a - среднее арифметическое,
n - число измерений параметра,
a i - измеренное значение на i-м шаге.
Показатель эксцесса
Показатель эксцесса (E) и его ошибка (m e) рассчитывается по следующим формулам:
![]() , где
, где
Определяется как обобщающая характеристика размеров вариации признака в совокупности. Оно равно квадратному корню из среднего квадрата отклонений отдельных значений признака от средней арифметической, т.е. корень из и может быть найдена так:
1. Для первичного ряда:
2. Для вариационного ряда:

Преобразование формулы среднего квадратичного отклонени приводит ее к виду, более удобному для практических расчетов:
Среднее квадратичное отклонение определяет на сколько в среднем отклоняются конкретные варианты от их среднего значения, и к тому же является абсолютной мерой колеблемости признака и выражается в тех же единицах, что и варианты, и поэтому хорошо интерпретируется.
Примеры нахождения cреднего квадратического отклонения: ,
Для альтернативных признаков формула среднего квадратичного отклонения выглядит так:
![]()
где р - доля единиц в совокупности, обладающих определенным признаком;
q - доля единиц, не обладающих этим признаком.
Понятие среднего линейного отклонения
Среднее линейное отклонение определяется как средняя арифметическая абсолютных значений отклонений отдельных вариантов от .
1. Для первичного ряда:

2. Для вариационного ряда:
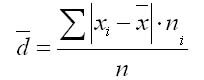
где сумма n - сумма частот вариационного ряда .
Пример нахождения cреднего линейного отклонения:
Преимущество среднего абсолютного отклонения как меры рассеивания перед размахом вариации, очевидно, так как эта мера основана на учете всех возможных отклонений. Но этот показатель имеет существенные недостатки. Произвольные отбрасывания алгебраических знаков отклонений могут привести к тому, что математические свойства этого показателя являются далеко не элементарными. Это сильно затрудняет использование среднего абсолютного отклонения при решении задач, связанных с вероятностными расчетами.
Поэтому среднее линейное отклонение как мера вариации признака применяется в статистической практике редко, а именно тогда, когда суммирование показателей без учета знаков имеет экономический смысл. С его помощью, например, анализируется оборот внешней торговли, состав работающих, ритмичность производства и т. д.
Среднее квадратическое
Среднее квадратическое применяется , например, для вычисления средней величины сторон n квадратных участков, средних диаметров стволов, труб и т. д. Она подразделяется на два вида.
Средняя квадратичная простая. Если при замене индивидуальных величин признака на среднюю величину необходимо сохранить неизменной сумму квадратов исходных величин, то средняя будет являться квадратичной средней величиной.
Она является квадратным корнем из частного от деления суммы квадратов отдельных значений признака на их число:
Средняя квадратичная взвешенная вычисляется по формуле:

где f - признак веса.
Средняя кубическая
Средняя кубическая применяется
, например, при определении средней длины стороны и кубов. Она подразделяется на два вида.
Средняя кубическая простая:


При расчете средних величин и дисперсии в интервальных рядах распределения истинные значения признака заменяются центральными значениями интервалов, которые отличны от средней арифметической значений, включенных в интервал. Это приводит к возникновению систематической погрешности при расчете дисперсии. В.Ф. Шеппард определил, что погрешность в расчете дисперсии , вызванная применением сгруппированных данных, составляет 1/12 квадрата величины интервала как в сторону повышения, так и в сторону понижения величины дисперсии.
Поправка Шеппарда должна применяться, если распределение близко к нормальному, относится к признаку с непрерывным характером вариации, построено по значительному количеству исходных данных (n > 500). Однако исходя из того, что в ряде случаев обе погрешности, действуя в разных направлениях компенсируют друг друга, можно иногда отказаться от введения поправок.
Чем меньше значение дисперсии и среднего квадратического отклонения, тем однороднее совокупность и тем более типичной будет средняя величина.
В практике статистики часто возникает необходимость сравнения вариаций различных признаков. Например, большой интерес представляет сравнение вариаций возраста рабочих и их квалификации, стажа работы и размера заработной платы, себестоимости и прибыли, стажа работы и производительности труда и т.д. Для таких сопоставлений показатели абсолютной колеблемости признаков непригодны: нельзя сравнивать колеблемость стажа работы, выраженного в годах, с вариацией заработной платы, выраженной в рублях.
Для осуществления таких сравнений, а также сравнений колеблемости одного и того же признака в нескольких совокупностях с разными средним арифметическим используется относительный показатель вариации - коэффициент вариации.
Структурные средние
Для характеристики центральной тенденции в статистических распределениях не редко рационально вместе со средней арифметической использовать некоторое значение признака X, которое в силу определенных особенностей расположения в ряду распределения может характеризовать его уровень.
Это особенно важно тогда, когда в ряду распределения крайние значения признака имеют нечеткие границы. В связи с этим точное определение средней арифметической, как правило, невозможно, либо очень сложно. В таких случаях средний уровень можно определить, взяв, например, значение признака, которое расположено в середине ряда частот или которое чаще всего встречается в текущем ряду.
Такие значения зависят только от характера частот т. е. от структуры распределения. Они типичны по месту расположения в ряду частот, поэтому такие значения рассматриваются в качестве характеристик центра распределения и поэтому получили определение структурных средних. Они применяются для изучения внутреннего строения и структуры рядов распределения значений признака. К таким показателям относятся .